1교시
데이터 전처리
파이썬만으로 시각화는 불가능 시각화 툴인 판다스를 활용해야한다.
데이터 처리, 가공에서는 판다스를 가장 많이 쓴다.
판다스에서 db에 저장하거나 가공해서 sql에서 사용
#파일 불러오기
import pandas as pd
kbo = pd.read_csv("./kbo_국내.csv")
kbo.shape
EDA(Exploratory Data Analysis / 탐색적 데이터 분석)
* 전처리 전 단계 (먼저 데이터를 파악하는 단계이다, 데이터가 싱싱한지 결측치 이상치 등을 파악)
이상치 / 결측치 파악
kbo.isnull().sum()>> 특정 컬럼에 결측치가 많다면 바로 확인 필요

# 데이터 종류
양적데이터 : 숫자 (회사 지출비용, 순이익, 연봉 등)
질적데이터(범주형데이터) : 등급, 포지션 등
ㄴ 범주형 데이터 분류 : 1.순서가 없는 데이터(혈액형 등) 2.순서가 있는 데이터(등급, 고과 등)
데이터 타입에 따라서 적용할 수 있는 함수가 다르다.
kbo.describe()
kbo['연봉']
>> 연봉이지만 데이터 타입이 텍스트(object) 로 되어 있다. >> 데이터 타입을 바꿔야함.
#'만원'을 우선 없애기
kbo['연봉'].apply(lambda x : x.replace("만원",""))
>> 다만 아직도 object 이다 >> int 로 변경할 필요가 있음
#int로 만들고 그걸 ['연봉']에 덮어서 변환 하겠다.
kbo['연봉'] = kbo['연봉'].apply(lambda x : int(x.replace("만원","")))
kbo['연봉'].describe()
count = 연봉 갯수
mean = 평균
std = 표준편차
min = 최솟값
50% = 중앙값 (데이터 정렬 후 딱 중앙에 있는 사람을 뽑았을때)
max = 최대값
* 박스 플롯 그리기 (설치 필요)
#프로그램 설치
import matplotlib.pyplot as plt다만, 이뻐서 잘 안쓴다.
#맷플롯에서 추가 기능이 있는 프로그램
#초반에 맷플롯이 깔려 있지 않다면 오류
pip install seaborn
import seaborn as snssns.boxplot(data=kbo, x = '연봉')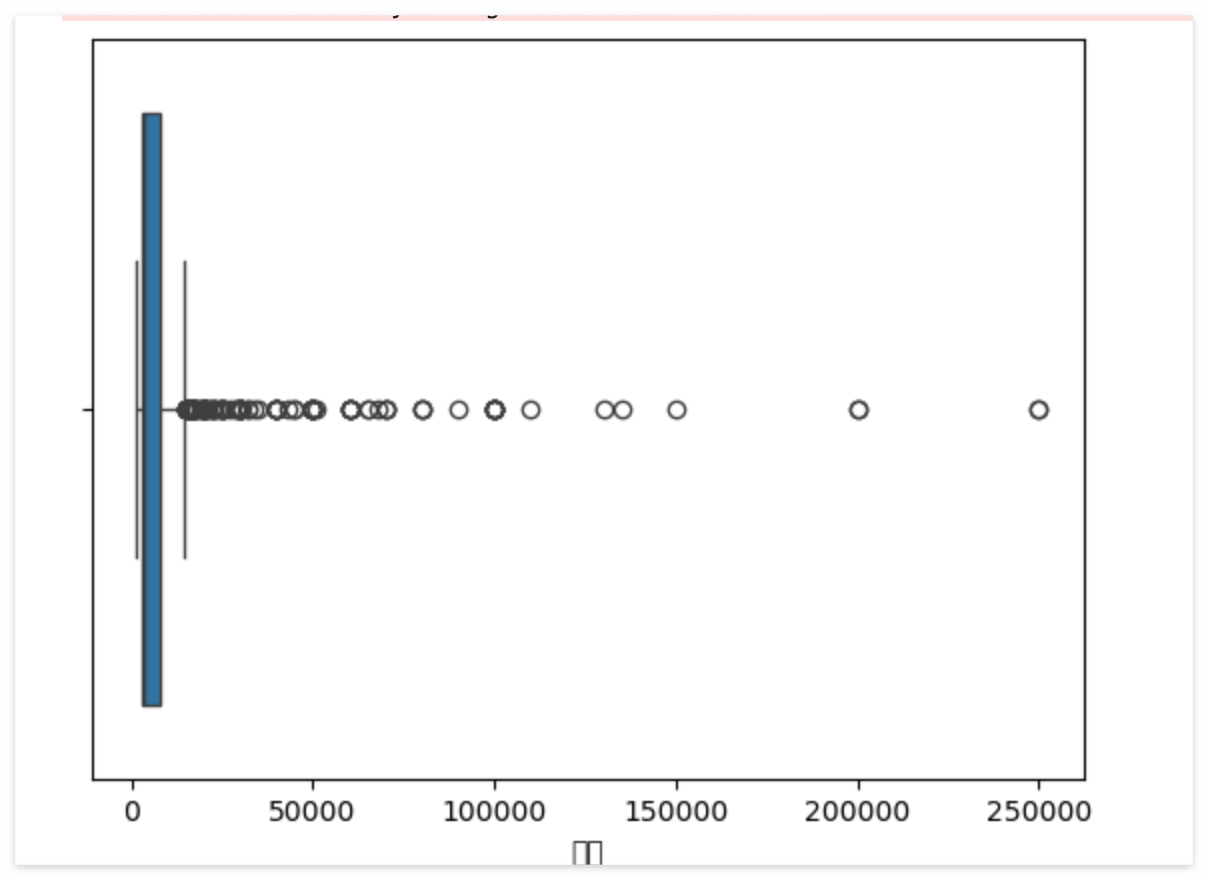
#한글 폰트가 안 보인다면, 맥은 다른 방법으로 다운 필요
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Malgun Gothic'
#sns.set_style("ggplot")sns.boxplot(data=kbo, x = '연봉', y='team')
plt.show()
이상치(outlier)
a = kbo[kbo['team']=='상무']['연봉']b = a.valuesb_mean = b.mean()b_meanimport numpy as np
np.sqrt(np.mean((b - b_mean) **2))
#자유도 0 / 1 은 다르다.
a.std(ddof=0)
help(a.std)> 결과

*띄어쓰기 없애기
#띄어쓰기 없어짐
'상무 '.strip()kbo['team'] = kbo['team'].apply(lambda x : x.strip())
* 팀이 상무인 선수만 추출
kbo[kbo['team']=='상무']

#연봉을 팀별로 보고 싶다.
#시리즈 형태
kbo.groupby(['team'])[['연봉']].mean()

* 데이터 솔팅
#데이터 프레임 형태, #특정 함수를 솔팅하고 싶다면 sort_values
kbo.groupby(['team'])[['연봉']].mean().sort_values(by=['연봉'], ascending=False)

#평균 말고 다른 것도 보고싶다. 여러개 보고 집계를 하고 싶어.
kbo.groupby(['team'])[['연봉']].agg(['mean','count','std','median'])

#포지션도 같이 보고싶어
kbo.groupby(['team','포지션'])[['연봉']].agg(['mean','count','std','median'])

#팀, 포지션 별로 연봉
kbo_agg = kbo.groupby(['team','포지션'])[['연봉']].mean().sort_values(by=['연봉'],ascending=False )

kbo_agg.index

#인덱스를 컬럼으로 하고 싶다면(인덱스에 있는 데이터가 컬럼으로 넘어왔따)
kbo_agg.reset_index()
#끝났다 싶으면 inplace
kbo_agg.reset_index(inplace=True)#팀은 내림차순, 포지션은 오름차순
kbo_agg.sort_values(by=['team','포지션'], ascending = [False, True])
#문자열로 집어넣어, 숫자에 콤마를 찍어라!
kbo_agg2['연봉2'] = kbo_agg2['연봉'].apply(lambda x : "{:,}".format(round(x)))
#선수를 가장 많이 배출한 초등학교 구하기
#- 기준으로 자르고 싶다.
kbo['경력'].str.split("-",expand=True)

학부 = kbo['경력'].str.split("-",expand=True)#고등학교 까지만 보고싶어
#iloc> 번호 갖고 위치를 얘기한다. ,오른쪽은 행 / ,왼쪽은 컬럼 / :표시는 전체를 의미한다. / 3 치면 2까지 보여준다.
학부.iloc[ : , :3]
학부 = 학부.iloc[ : , :3].copy()#컬럼에 이름 붙이기
학부.columns = ['초','중','고']
#각 값을 카운트 해줘 = value_counts()
학부['초'].value_counts()
#비율을 알고 싶다면
학부['초'].value_counts(normalize=True)

#컬럼명 바꾸기
학부.rename(columns={'초':'초등학교','중':'중학교','고':'고등학교'})
#이상이 없는것을 확있했다면 바로 적용 필요
학부.rename(columns={'초':'초등학교','중':'중학교','고':'고등학교'}, inplace=True)
#이름으로 적용된다. *숫자는 인덱스
학부.loc[ : , ['초등학교','중학교',]]
#행을 구분하자면 #이름이다.
학부.loc[ 0:2 , ['초등학교','중학교',]]

학부.iloc[ 0:2 ,[0,1]]
#concat 으로 데이터 합침, axis 1은 가로로, axis 0 은 세로로 붙인다
pd.concat([kbo,학부],axis=1)
#전제조건 raw 값이 같아야해, 인덱스 같은 정보가 있어야해
kbo2 = pd.concat([kbo, 학부], axis=1)#부산수영초 뽑기
kbo2[kbo2['초등학교'] == '부산수영초'].groupby(['team'])[['초등학교']].count().sort_values(by=['초등학교'],ascending=False)
#team 은 인덱스로 들어갔어
#인덱스를 컬럼으로 변경하고 싶을때 #(/는 다음 줄도 같은 행에 있다는 것을 알려주는 것
kbo2[kbo2['초등학교'] =='부산수영초'].groupby(\
['team'], as_index=False)[['초등학교']].count().sort_values(by=['초등학교'], ascending=False)
#수영초가 들어간 팀
a= kbo2[kbo2['초등학교'] =='부산수영초'].groupby(\
['team'], as_index=False)[['초등학교']].count().sort_values(by=['초등학교'], ascending=False)['team'].tolist()
b = kbo2.team.unique().tolist()

#a와 b 차 집합을 하면 수영초가 없는 팀이 나온다.
set(b)- set(a)

#각 팀별로 연봉 많이 받는 사람 한명 확인
kbo2.sort_values(by=['연봉'], ascending=False).groupby(['team']).first()
#bmi가 높은 사람 뽑아보기
#기존 변수에서 새로운 변수 만들었음 >> 파생변수
#신장 파생변수 만들기
kbo2['신장'] = kbo2['신장/체중'].apply(lambda x : int(x.split("/")[0].replace("cm","")))#bmi
kbo2['체중'] / (kbo2['신장']/100) **2#체중 파생변수 만들기
kbo2['체중'] = kbo2['신장/체중'].apply(lambda x : int(x.split("/")[1].replace("kg","")))
kbo2['bmi'] = kbo2['체중'] / (kbo2['신장']/100) **2#팀별로 bmi 가장 높은 사람 뽑아보기
kbo2.sort_values(by=['bmi'], ascending=False).groupby(['team']).first()
#axis = 1 은 컬럼이라는 뜻 #inplace를 해야 적용
kbo2.drop(['신장/체중','경력'], axis =1, inplace=True)
#컬럼 위치를 바꾸고 싶어
kbo2.columns
> 칼럼을 먼저 뽑고 복사
kbo2 = kbo2[['team','선수명', '등번호', '생년월일', '포지션', '입단 계약금', '연봉', '지명순위', '입단년도',
'초등학교', '중학교','고등학교', '신장', '체중', 'bmi']].copy()
kbo2[kbo2['team'] == 'KIA 타이거즈']
*바차트
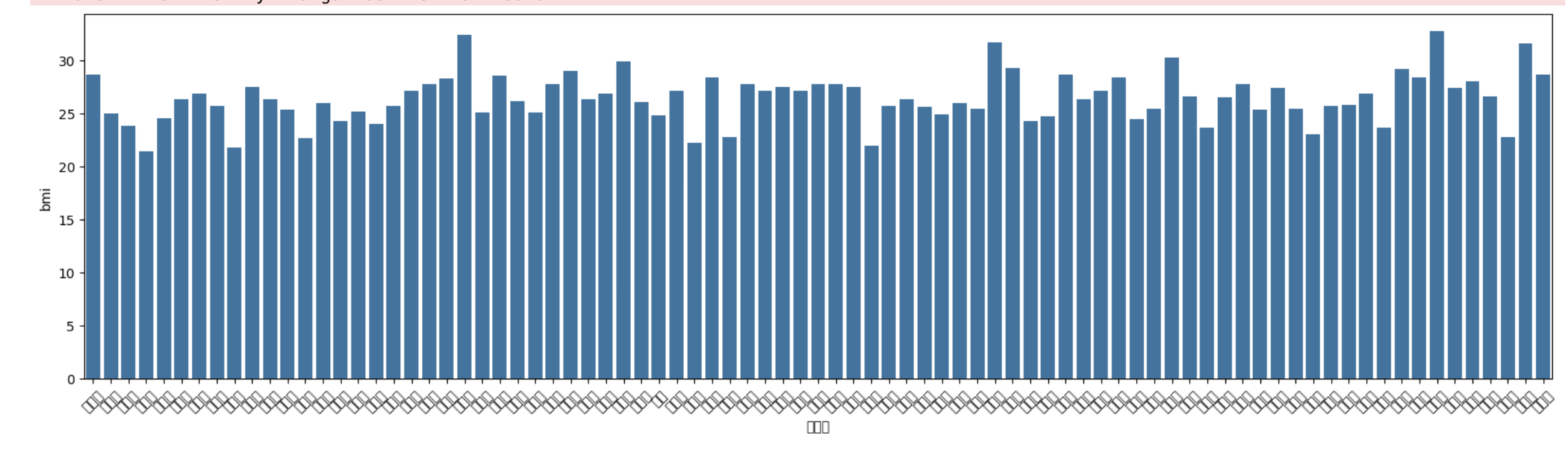
kbo2[kbo2['team'] == 'KIA 타이거즈']['bmi'].plot(kind='bar')
sns.barplot(x = kbo2[kbo2['team'] == 'KIA 타이거즈']['선수명'], y = kbo2[kbo2['team'] == 'KIA 타이거즈']['bmi'])
#그림을 키우고 싶다면?
plt.figure(figsize=(20,5))
sns.barplot(x = kbo2[kbo2['team'] == 'KIA 타이거즈']['선수명'], y = kbo2[kbo2['team'] == 'KIA 타이거즈']['bmi'])
#차트에다가 이름을 45도로 꺽어서 넣음
plt.figure(figsize=(20,5))
chart = sns.barplot(x = kbo2[kbo2['team'] == 'KIA 타이거즈']['선수명'], y = kbo2[kbo2['team'] == 'KIA 타이거즈']['bmi'])
chart.set_xticklabels(chart.get_xticklabels(), rotation=45)
웹을 제어 하고 싶다면? #셀레니움
#웹드라이버매니저 설치해야 함
#회사에서 쓰게되면 파이썬 버전이 여러개 나눠짐.
#크롬을 제어할 있는 것 셀레니움
#이것을 악용하게 되면 매크로, 봇 이 된다.
#셀레니움 자동화 테스트 하다가 용도가 변경 된 것
pip install selenium
pip install webdriver_manager
#virtualenv >> 파이썬 친해지고 그러면 프라이버시 모드로 활용 가능
#크롬 버전 바꿔야함
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
driver = webdriver.Chrome(service=Service(ChromeDriverManager(driver_version="131.0.6778.109").install()))# 그럼 data; 창이 뜬다 >> 창이 팝업 된 뒤에 뒤에 것들이 실행 된다.
#get 은 내가 chrome을 통해서 네이버 카페로 이동 하겠다.
driver.get("http://cafe.naver.com")
driver.get("https://www.koreabaseball.com/Record/Player/HitterBasic/BasicOld.aspx")from selenium.webdriver.common.by import Bydriver.find_element(By.CSS_SELECTOR, "#contents > div.sub-content > div.tab-depth2 > ul > li:nth-child(2) > a").click()>> 위의 # contents 찾는 법은 아래 참고
driver.get("https://www.koreabaseball.com/Record/Player/HitterBasic/BasicOld.aspx")

from bs4 import BeautifulSoupimport io
pd.read_html(io.StringIO(driver.page_source))[0]driver.find_element(By.CSS_SELECTOR,
"#cphContents_cphContents_cphContents_ucPager_btnNo2").click()pg1 = pd.read_html(io.StringIO(driver.page_source))[0]driver.find_element(By.CSS_SELECTOR,
"#cphContents_cphContents_cphContents_ucPager_btnNo2").click()#데이터 로딩이 된 후 가져와야 한다.
import time
time.sleep(2)
pg2 = pd.read_html(io.StringIO(driver.page_source))[0]타자 = pd.concat([pg1],[pg2] )타자 = pd.concat([pg1,pg2], ignore_index=True)타자.columns#corr 만 쓰면 상관 관계가 나온다.
타자[[ 'AVG', 'G', 'PA', 'AB', 'R', 'H', '2B', '3B', 'HR',
'TB', 'RBI', 'SAC', 'SF']].corr()#시각화 -> 히트맵
#상관관계를 볼때는 데이터 자체가 int 여야 한다.
sns.heatmap(타자[[ 'AVG', 'G', 'PA', 'AB', 'R', 'H', '2B', '3B', 'HR',
'TB', 'RBI', 'SAC', 'SF']].corr())
#타자 기준으로 kbo 데이터를 합치고 싶다.
#팀, 이름으로 조인을 해야하지만 중복되어서 데이터가 이상해 질수 있어
#팀을 처리를 해줘야해
kbo2['팀명'] = kbo2['team'].apply(lambda x : x.split()[0])kbo2['팀명'].unique()타자['팀명'].unique()
#merge 를 한다
#합칠떄 기준을 먼저 왼쪽에 적는다.
#how 에는 inner, right, outer 도 쓸 수 있음
타자2 = pd.merge(타자, kbo2, left_on=['팀명', '선수명'], right_on=['팀명','선수명'], how='inner')
타자2[['AVG','연봉']].corr()
#히스토그램
kbo2['포지션'].hist()