CAR_RENTAL_COMPANY_CAR테이블과CAR_RENTAL_COMPANY_RENTAL_HISTORY테이블에서 자동차 종류가 '세단'인 자동차들 중 10월에 대여를 시작한 기록이 있는 자동차 ID 리스트를 출력하는 SQL문을 작성해주세요. 자동차 ID 리스트는 중복이 없어야 하며, 자동차 ID를 기준으로 내림차순 정렬해주세요.
해결 방식 :
-- 자동차 id 리스트(NO중복) >> GROUP BY -- 자동차 종류가 '세단'인 자동차 >> WHERE = '세단' -- 10월에 대여 시작한 기록 >> WHERE MONTH = 10 -- CAR_ID 내림차순
결과 : 정답
답안 :
SELECT CH.CAR_ID
FROM CAR_RENTAL_COMPANY_RENTAL_HISTORY AS CH
LEFT JOIN CAR_RENTAL_COMPANY_CAR AS CC ON CH.CAR_ID = CC.CAR_ID
WHERE MONTH(CH.START_DATE) = 10
AND CC.CAR_TYPE = '세단'
GROUP BY 1
ORDER BY 1 DESC
다른 풀이법 :
1. 세단 찾기
- CAR_TYPE IN ('세단')
- SELECT DISTINCT(CC.CAR_ID)
2. 10월
- DATE_FORMAT(START_DATE, '%Y-%m-%d') like '2022-10%'
입양 게시판에 동물 정보를 게시하려 합니다. 동물의 생물 종, 이름, 성별 및 중성화 여부를 아이디 순으로 조회하는 SQL문을 작성해주세요. 이때 프로그래밍을 모르는 사람들은 NULL이라는 기호를 모르기 때문에, 이름이 없는 동물의 이름은 "No name"으로 표시해 주세요.
문제 해결 방식 :
-- 동물의 생물 종, 이름, 성별 및 중성화 여부 -- ORDER BY 아이디 -- NULL > NO NAME 으로 변경 : ISNULL
사용 함수 : CASE WHEN, ISNULL
결과 : 정답
SELECT ANIMAL_TYPE, CASE WHEN NAME IS NULL THEN 'No name' ELSE NAME END AS NAME, SEX_UPON_INTAKE
FROM ANIMAL_INS
ORDER BY ANIMAL_ID
다른 풀이 : IFNULL 을 쓰면 더 깔끔함
SELECT ANIMAL_TYPE, IFNULL(NAME, 'No name') as NAME, SEX_UPON_INTAKE
FROM ANIMAL_INS
ORDER BY ANIMAL_ID
보호소에 돌아가신 할머니가 기르던 개를 찾는 사람이 찾아왔습니다. 이 사람이 말하길 할머니가 기르던 개는 이름에 'el'이 들어간다고 합니다. 동물 보호소에 들어온 동물 이름 중, 이름에 "EL"이 들어가는 개의 아이디와 이름을 조회하는 SQL문을 작성해주세요. 이때 결과는 이름 순으로 조회해주세요. 단, 이름의 대소문자는 구분하지 않습니다.
문제 해결 방식 :
-- 이름에 el 들어감 LIKE '%el%' -- 이름순 조회 , 대소문자 구문하지 않음
-- '개'를 찾음
사용 함수 : LIKE
결과 : 틀림
틀린 이유 : '개'를 찾는 다는 조건 누락
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
WHERE NAME LIKE '%el%'
ORDER BY 2 ;
답안 :
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
WHERE NAME LIKE '%el%'
AND ANIMAL_TYPE = 'DOG'
ORDER BY 2 ;
USED_GOODS_BOARD와USED_GOODS_REPLY테이블에서 2022년 10월에 작성된 게시글 제목, 게시글 ID, 댓글 ID, 댓글 작성자 ID, 댓글 내용, 댓글 작성일을 조회하는 SQL문을 작성해주세요. 결과는 댓글 작성일을 기준으로 오름차순 정렬해주시고, 댓글 작성일이 같다면 게시글 제목을 기준으로 오름차순 정렬해주세요.
문제 해결 방식 :
-- 코드를 입력하세요 -- 2022년 10월에 작성된 게시글 제목, 게시글 ID, 댓글 ID, 댓글 작성자 ID, 댓글 내용, 댓글 작성일 -- ORDER BY 댓글 작성일 ASC / 같다면 게시글 제목 ASC
사용 함수 : DATE_FORMAT, INNER JOIN, LIKE
결과 : 정답
SELECT UGB.TITLE, UGB.BOARD_ID, UGR.REPLY_ID, UGR.WRITER_ID, UGR.CONTENTS, DATE_FORMAT(UGR.CREATED_DATE, '%Y-%m-%d') as CREATED_DATE
FROM USED_GOODS_BOARD AS UGB
INNER JOIN USED_GOODS_REPLY UGR ON UGB.BOARD_ID = UGR.BOARD_ID
WHERE UGB.CREATED_DATE LIKE '2022-10%'
ORDER BY 6 ASC, 1 ASC
다른 풀이 방법 :
SUBSTRING 사용
BETWEEN 사용
SELECT
B.TITLE,
B.BOARD_ID,
R.REPLY_ID,
R.WRITER_ID,
R.CONTENTS,
SUBSTRING(R.CREATED_DATE, 1, 10) AS CREATED_DATE
FROM
USED_GOODS_BOARD AS B JOIN USED_GOODS_REPLY AS R
on B.BOARD_ID = R.BOARD_ID
WHERE B.CREATED_DATE BETWEEN '2022-10-01' AND '2022-10-31'
ORDER BY R.CREATED_DATE, B.TITLE
CAR_RENTAL_COMPANY_RENTAL_HISTORY테이블에서 대여 시작일이 2022년 9월에 속하는 대여 기록에 대해서 대여 기간이 30일 이상이면 '장기 대여' 그렇지 않으면 '단기 대여' 로 표시하는 컬럼(컬럼명:RENT_TYPE)을 추가하여 대여기록을 출력하는 SQL문을 작성해주세요. 결과는 대여 기록 ID를 기준으로 내림차순 정렬해주세요.
문제 해결 방식 :
-- WHERE 에서 대여 시작일 2022년 9월 -- CASE WHEN 으로 대여기간 30일 이상 >= 30 '장기대여' / 아니면 '단기 대여' >> 컬럼 RENT_TYPE -- ORDER BY 대여 기록 ID DESC
사용 함수 : DATE_FORMAT, CASE WHEN, MONTH
결과 : 틀림
SELECT TB.*
FROM(
SELECT HISTORY_ID, CAR_ID, DATE_FORMAT(START_DATE, '%Y-%m-%d') AS START_DATE, DATE_FORMAT(END_DATE, '%Y-%m-%d') AS END_DATE , CASE WHEN DATEDIFF(END_DATE, START_DATE) >= 30 THEN '장기대여'
ELSE '단기대여' END AS RENT_TYPE
from CAR_RENTAL_COMPANY_RENTAL_HISTORY) TB
WHERE MONTH(TB.START_DATE) = 09
ORDER BY 1 DESC
틀린 이유 : 빌린 당일날 반납한 것은 1일 대여한 것으로 쳐야 함.. 30을 29로 바꾸니 정답 확인
SELECT TB.*
FROM(
SELECT HISTORY_ID, CAR_ID, DATE_FORMAT(START_DATE, '%Y-%m-%d') AS START_DATE, DATE_FORMAT(END_DATE, '%Y-%m-%d') AS END_DATE , CASE WHEN DATEDIFF(END_DATE, START_DATE) >= 29 THEN '장기 대여'
ELSE '단기 대여' END AS RENT_TYPE
from CAR_RENTAL_COMPANY_RENTAL_HISTORY) TB
WHERE MONTH(TB.START_DATE) = 09
ORDER BY 1 DESC
다른 풀이법 :
1. WHERE 을 다르게 사용
WHERE START_DATE LIKE '2022-09%'
WHERE YEAR(START_DATE) = 2022 AND MONTH(START_DATE) = 9
* DATEDIFF
두 날짜 간의 차이를 단순히 일(day) 단위로 계산
* TIMESTAMPDIFF 사용
- YEAR
- MONTH
- DAY
- HOUR
- MINUTE
- SECOND
예제
SELECT DATEDIFF(MONTH, '2023-01-01', '2024-09-19') AS month_diff ;
1) 경력 계산 : 직원의 입사일과 현재 날짜 사이의 차이를 계산할 때
SELECT
employee_name,
DATEDIFF(NOW(), hire_date) AS day_worked
FROM employees;
2) 이벤트 간격 계산 : 두 이벤트 사이의 시간을 측정할 때
SELECT
event_name,
TIMESTAMPDIFF(HOUR, start_time, end_time) AS event_duration_hours
FROM events ;
3) 유효 기간 계산 : 유효기간이나 만료일을 계산할 때
SELECT
product_name,
DATEDIFF(expire_date, NOW()) AS days_until_expiry
FROM products
평균 길이를 나타내는 컬럼 명은 AVERAGE_LENGTH로 해주세요. 평균 길이는 소수점 3째자리에서 반올림하며, 10cm 이하의 물고기들은 10cm 로 취급하여 평균 길이를 구해주세요.
SELECT ROUND(AVG(IF(LENGTH IS NULL,10,LENGTH)),2)AS AVERAGE_LENGTH
FROM FISH_INFO
결과 :
다른 풀이 :
-- 일반 풀이
SELECT ROUND(AVG(
CASE WHEN LENGTH IS NULL THEN 10
WHEN LENGTH <=10 THEN 10
ELSE LENGTH
END),2) AS AVERAGE_LENGTH
FROM FISH_INFO
-- 서브쿼리를 활용한 풀이
SELECT ROUND(AVG(A.LENGTH),2) AS AVERAGE_LENGTH
FROM(
SELECT ID, FISH_TYPE,
CASE WHEN LENGTH IS NULL THEN 10
WHEN LENGTH <= 10 THEN 10
ELSE LENGTH
END AS LENGTH
FROM FISH_INFO ) A
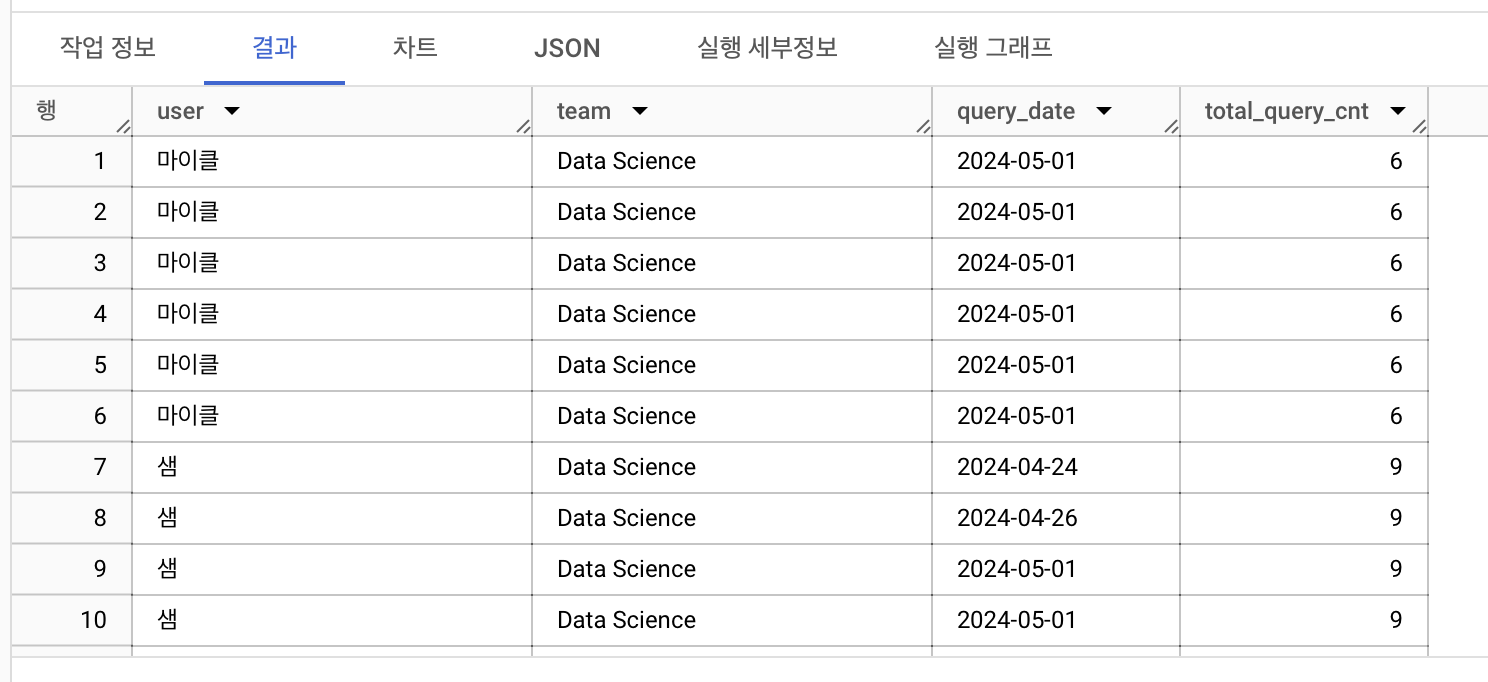
사용자별 쿼리를 실행한 총 횟수를 구하는 쿼리를 작성해주세요. 단, group by 를 사용해서 집계하는 것이 아닌 query_logs의 데이터의 우측에 새로운 컬럼을 만들어주세요. -- 사용자별 쿼리를 실행한 총 횟수 : count() 전체 실행 -- over(partition by user)
select *, count(query_date) over(partition by user) as total_query_cnt
from advanced.query_logs
order by user, query_date
결과
연습 문제 2
데이터 테이블 : query_logs
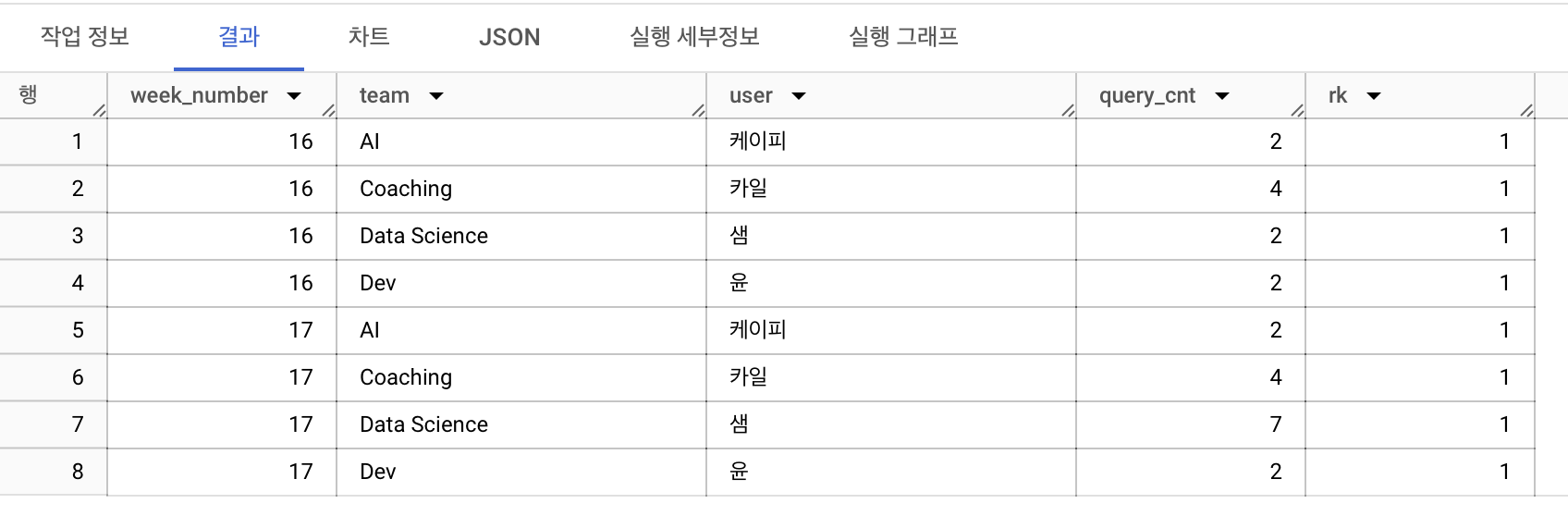
주차별로 팀 내에 쿼리를 많이 실행한 수를 구한 후, 실행한 수를 활용해 랭킹을 구해주세요.
단, 랭킹이 1등인 사람만 결과가 보이도록 해주세요.
with query_cnt_by_team as(
select
extract(week from query_date) as week_number,
team,
user,
count(user) as query_cnt
from advanced.query_logs
group by all)
select *,
rank() over(partition by week_number, team order by query_cnt desc) as rk
from query_cnt_by_team
-- qualify : 윈도우 함수의 조건을 설정할 때 사용한다.
-- where 을 쓸 수 있지만 그럴 경우 서브쿼리를 활용해야함
qualify rk = 1
order by week_number, team, query_cnt desc
--
결과
연습 문제 3
데이터 테이블 : 2번 문제에서 사용한 주차별 쿼리 사용
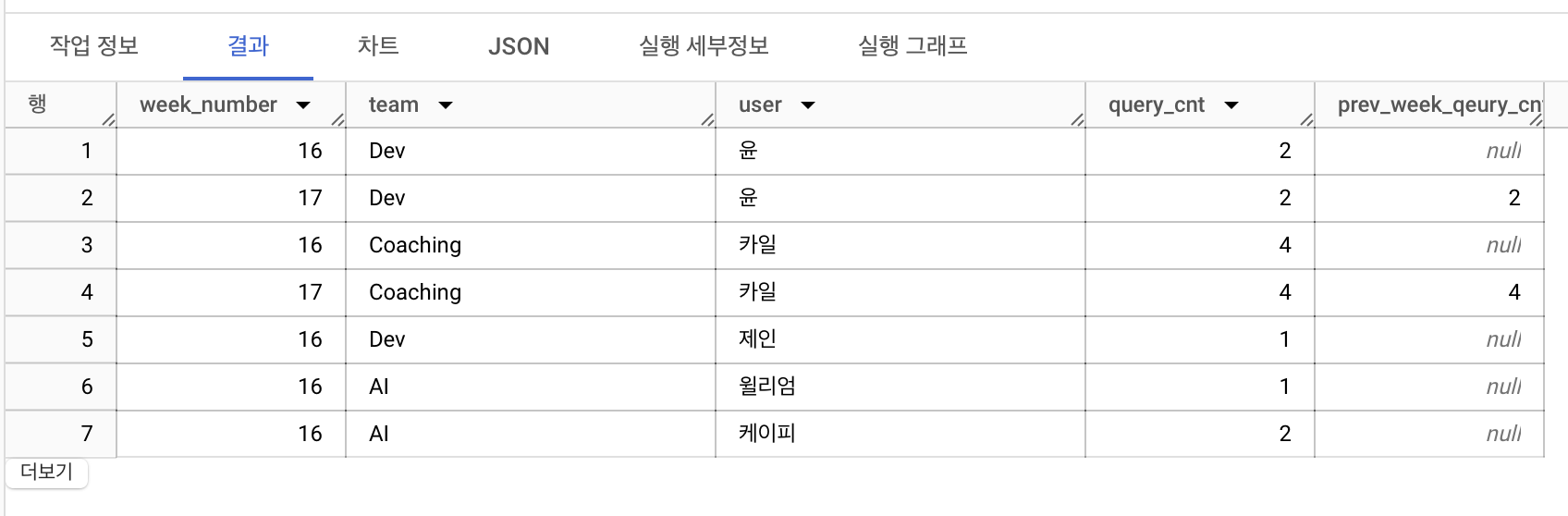
쿼리를 실행한 시점 기준 1주 전에 쿼리 실횅수를 별도의 컬럼으로 확인할 수 있는 쿼리를 작성해주세요.
with query_cnt_by_team as(
select
extract(week from query_date) as week_number,
team,
user,
count(user) as query_cnt
from advanced.query_logs
group by all)
select *,
lag(query_cnt,1) over(partition by user order by week_number) as prev_week_qeury_cnt
from query_cnt_by_team
-- over(partition by user)
결과
연습 문제 4
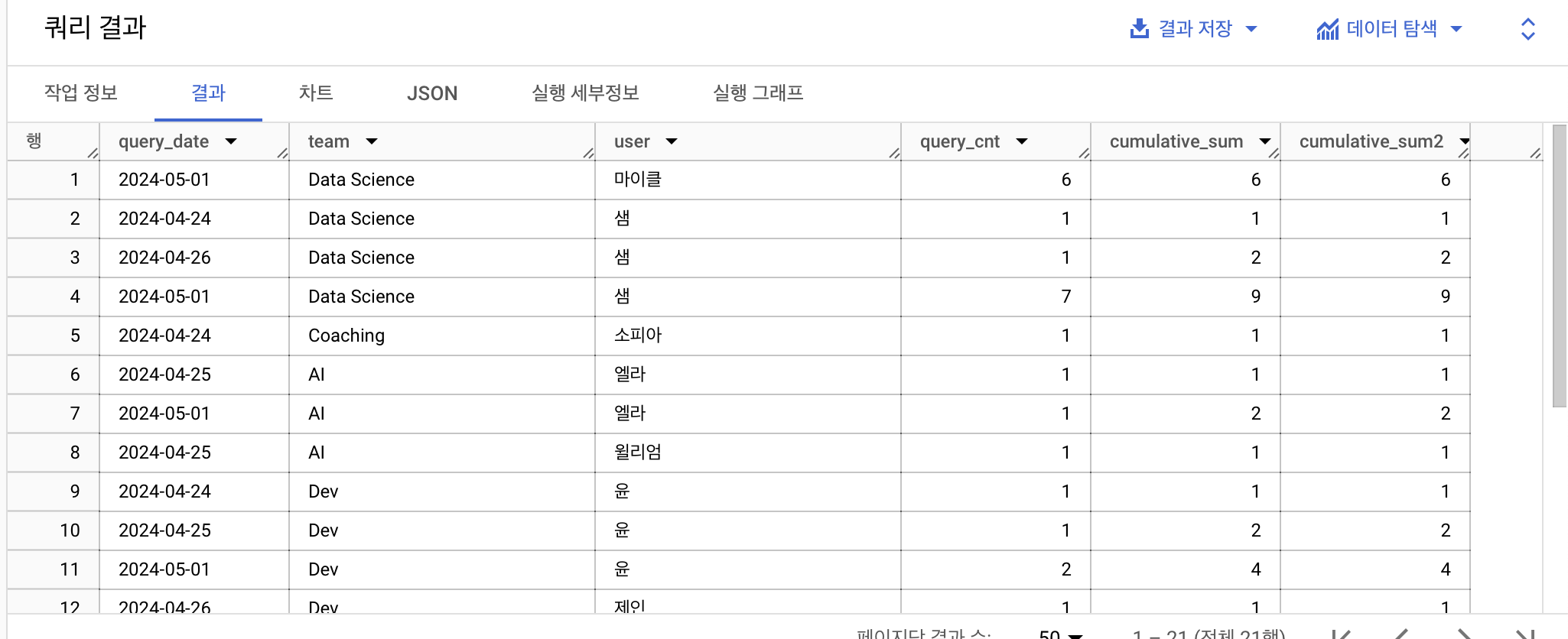
시간의 흐름에 따라, 일자별로 유저가 실행한 누적 쿼리 수를 작성해 주세요.
--누적 쿼리 : 과거의 시간(unbounded preceding) 부터 curren row 까지
--출제 의도 : default frame에 대해 알려드리고 싶었음.
select *,
sum(query_cnt) over(partition by user order by query_date) as cumulative_sum,
sum(query_cnt) over(partition by user order by query_date rows between unbounded preceding and current row) as cumulative_sum2
-- frame의 default 값 : unbounded preceding ~~ current row
from(
select
query_date,
team,
user,
count(user) as query_cnt
from advanced.query_logs
group by all)
-- # qualify cumulative_sum != cumulative_sum2
--where, qualify 조건 설정해서 2가지 값이 모두 같은지 비교 => 모두 같으면 != 연산 결과에 반환하는 값이 없을 것
order by user, query_date
결과
연습 문제 5
다음 데이터는 주문 횟수를 나타낸 데이터입니다. 만약 주문 횟수가 없으면 NULL로 기록됩니다.
이런 데이터에서 NULL 값이라고 되어있는 부분을 바로. 이전 날짜의 값으로 채워주는 쿼리를 작성해주세요.
WITH raw_data AS (
SELECT DATE '2024-05-01' AS date, 15 AS number_of_orders UNION ALL
SELECT DATE '2024-05-02', 13 UNION ALL
SELECT DATE '2024-05-03', NULL UNION ALL
SELECT DATE '2024-05-04', 16 UNION ALL
SELECT DATE '2024-05-05', NULL UNION ALL
SELECT DATE '2024-05-06', 18 UNION ALL
SELECT DATE '2024-05-07', 20 UNION ALL
SELECT DATE '2024-05-08', NULL UNION ALL
SELECT DATE '2024-05-09', 13 UNION ALL
SELECT DATE '2024-05-10', 14 UNION ALL
SELECT DATE '2024-05-11', NULL UNION ALL
SELECT DATE '2024-05-12', NULL
)
-- 윈도우 함수의 first_value, last_value 에선 기본적으로 null을 포함해서 연상
-- null을 제외하고 싶으면 ignore nulls 함수를 쓰자
--ignore x
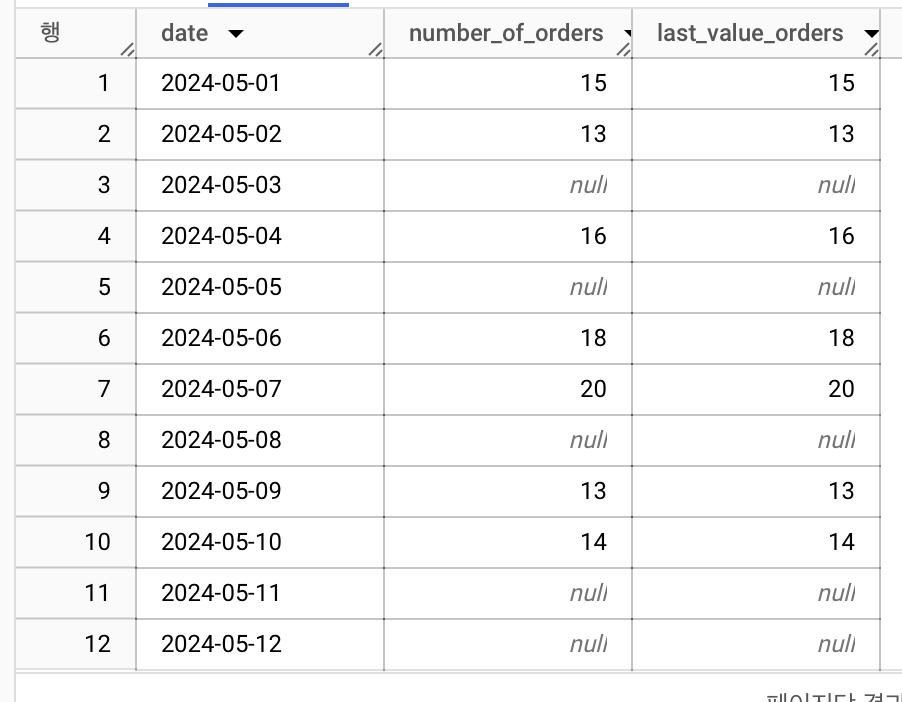
select *, last_value(number_of_orders) over(order by date) as last_value_orders
from raw_data
결과
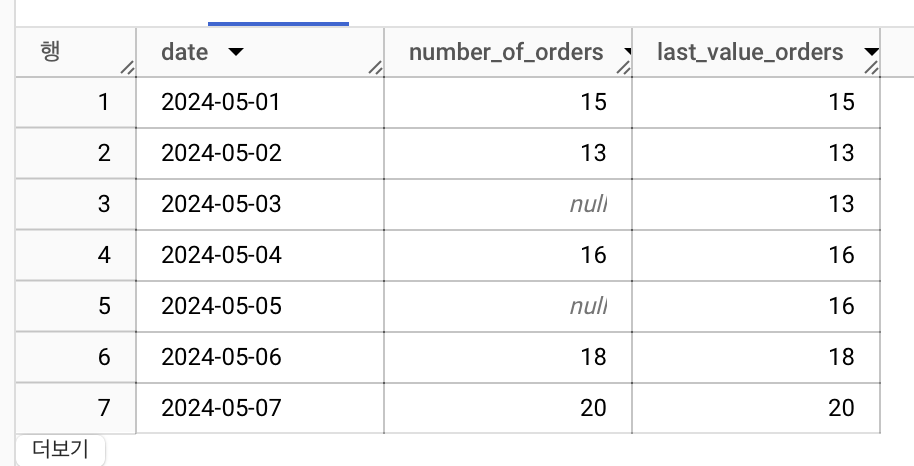
-- ignore 사용
select *, last_value(number_of_orders ignore nulls ) over(order by date) as last_value_orders
from raw_data
결과
연습 문제 6
5번 문제에서 null을 채운 후, 2일 전 ~ 현재 데이터의 평균을 구하는 쿼리를 작성해주세요 (이동평균)
WITH raw_data AS (
SELECT DATE '2024-05-01' AS date, 15 AS number_of_orders UNION ALL
SELECT DATE '2024-05-02', 13 UNION ALL
SELECT DATE '2024-05-03', NULL UNION ALL
SELECT DATE '2024-05-04', 16 UNION ALL
SELECT DATE '2024-05-05', NULL UNION ALL
SELECT DATE '2024-05-06', 18 UNION ALL
SELECT DATE '2024-05-07', 20 UNION ALL
SELECT DATE '2024-05-08', NULL UNION ALL
SELECT DATE '2024-05-09', 13 UNION ALL
SELECT DATE '2024-05-10', 14 UNION ALL
SELECT DATE '2024-05-11', NULL UNION ALL
SELECT DATE '2024-05-12', NULL
)
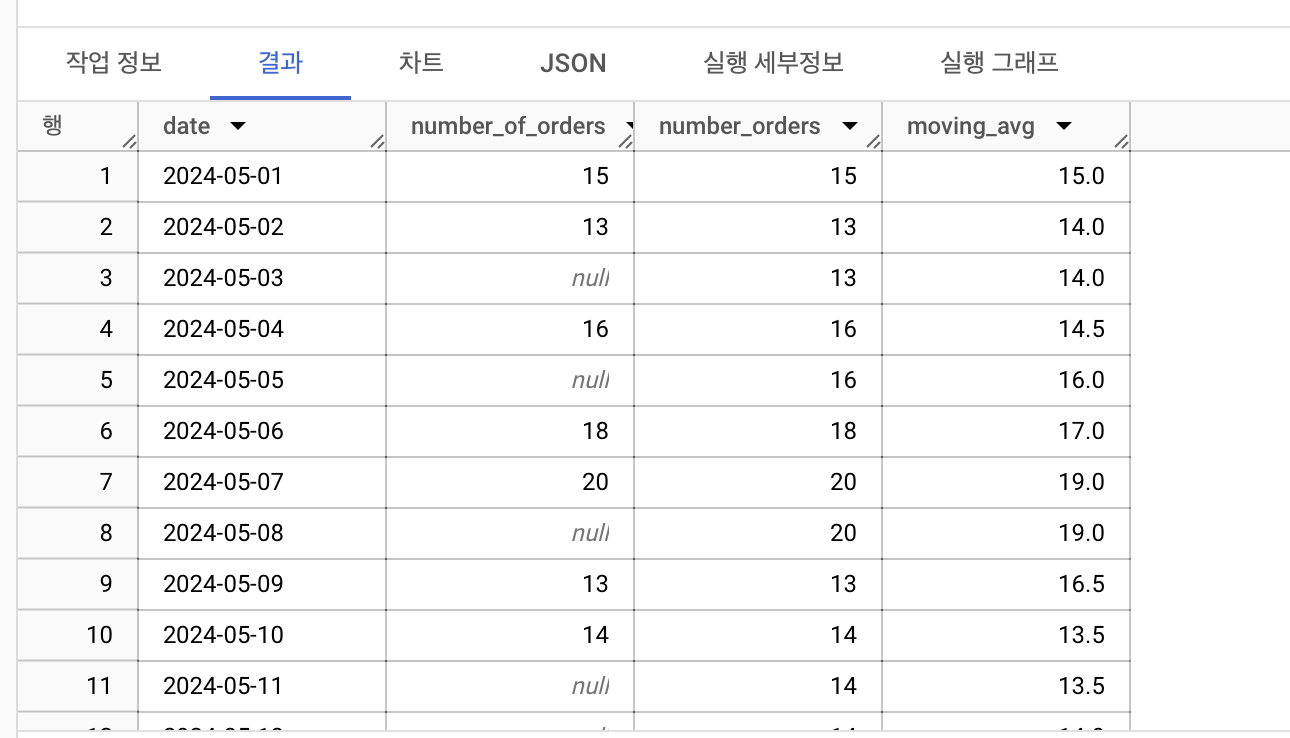
, filled_data as(
select *, last_value(number_of_orders ignore nulls ) over(order by date) as number_orders
from raw_data)
-- with 문을 또 쓸 수 없으니 , 로 구분해 주면 된다.
select * , avg(number_of_orders) over(order by date rows between 2 preceding and current row) as moving_avg
from filled_data
-- frame: 2일 전 => between 2 preceding and current row